Автозаполнение Jupyter + PySpark
Извините за вопрос новичка Jupyter -
Я установил Jupyter и PySpark, используя это руководство - https://blog.sicara.com/get-started-pyspark-jupyter-guide-tutorial-ae2fe84f594f
Кажется, все работает, но у меня нет автозаполнения для некоторых «вложенных» функций.
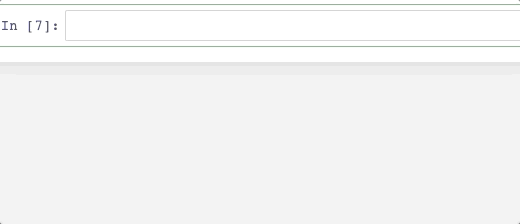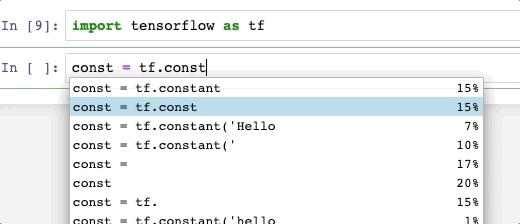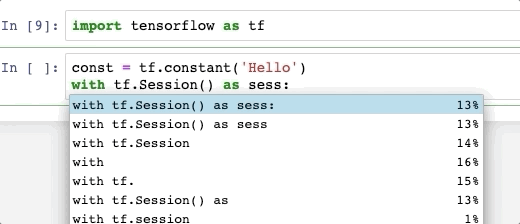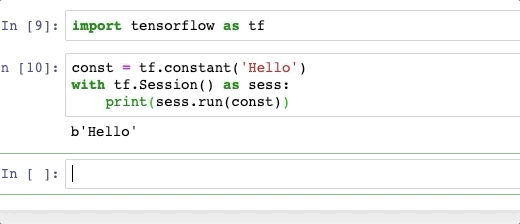
Например - запуск "spark" -> я получаю сеанс spark
Когда я нажимаю вкладку после «искры». -> Я получаю список возможных предложений, таких как "читать"
Но нажатие tab после spark.read. ничего не показывай. Хотя я бы ожидал показать такие параметры, как «CSV», «Паркват» и т.д....
Важное примечание: запуск "spark.read.csv("1.txt")" работает
Также - пытался применить предложения от Автозаполнение вкладки `ipython` не работает с импортированным модулем, но это не сработало.
Что мне не хватает?
спасибо за предложение! как я могу это проверить? Кстати, когда я запускаю a= spark.read. и позже запустите a. <tab> Я получил все предложения, на которые рассчитывал
Вы можете наблюдать за использованием ресурсов и получить процесс, ответственный за завершение, я предполагаю, что использование ЦП резко возрастет во время синтаксического анализа библиотеки. То, что вы написали выше, может указывать на то, что это действительно так, возможно, кто-то еще сможет точно определить проблему.






Ответы 2
Я разработал расширение Jupyter Notebook Extension на основе TabNine, которое обеспечивает автодополнение кода на основе глубокого обучения. Конечно, он также поддерживает Pyspark. Вот ссылка на Github моей работы: юпитер-табнин.
Он уже доступен на pypi-индекс. Просто введите следующие команды, а затем наслаждайтесь :)
pip3 install jupyter-tabnine
jupyter nbextension install --py jupyter_tabnine
jupyter nbextension enable --py jupyter_tabnine
jupyter serverextension enable --py jupyter_tabnine
Это можно сделать, вручную импортировав или установив переменную .env для python.
- В сеансе Python/блокноте.
import rlcompleter, readline
readline.parse_and_bind("tab: complete")
- Включить его при запуске PySpark — мой случай.
.bash_profile
export PYTHONSTARTUP = "$HOME/.pythonrc"
.pythonrc
import rlcompleter, readline
readline.parse_and_bind("tab: complete")
Причина может быть более прозаичной; Я предполагаю, что искра довольно тяжелая, поэтому для разбора зависимостей требуется много времени. Если количество возвращенных предложений слишком велико (или это занимает слишком много времени), процесс может быть убит, вы можете проверить это.