Как наиболее эффективно обрабатывать большое количество файловых дескрипторов?
Кажется, есть несколько вариантов, доступных для программ, которые обрабатывают большое количество подключений к сокетам (например, веб-службы, системы p2p и т. д.).
- Создайте отдельный поток для обработки ввода-вывода для каждого сокета.
- Используйте системный вызов Выбрать для мультиплексирования ввода-вывода в один поток.
- Используйте системный вызов голосование для мультиплексирования ввода-вывода (заменяя select).
- Используйте системные вызовы эполл, чтобы избежать многократной отправки fd сокетов через границы пользователя / системы.
- Создайте несколько потоков ввода-вывода, каждый из которых мультиплексирует относительно небольшой набор из общего числа подключений, используя API опроса.
- Согласно №5, за исключением использования API epoll для создания отдельного объекта epoll для каждого независимого потока ввода-вывода.
На многоядерном процессоре я ожидал бы, что № 5 или № 6 будут иметь лучшую производительность, но у меня нет никаких жестких данных, подтверждающих это. При поиске в сети была обнаружена страница это, описывающая опыт автора при тестировании подходов № 2, № 3 и № 4 выше. К сожалению, этой веб-странице около 7 лет, и на ней не обнаружено явных последних обновлений.
Итак, мой вопрос: какой из этих подходов люди считают наиболее эффективным и / или есть ли другой подход, который работает лучше, чем любой из перечисленных выше? Ссылки на графики из реальной жизни, технические документы и / или записи, доступные в Интернете, будут приветствоваться.





Ответы 4
Я широко использую epoll (), и он хорошо работает. У меня обычно есть тысячи активных розеток, и я тестирую до 131 072 розеток. И epoll () всегда справится с этим.
Я использую несколько потоков, каждый из которых опрашивает подмножество сокетов. Это усложняет код, но в полной мере использует преимущества многоядерных процессоров.
По моему опыту, у вас будет лучшая производительность с №6.
Я также рекомендую вам изучить libevent, чтобы абстрагироваться от некоторых из этих деталей. По крайней мере, вы сможете увидеть некоторые из их тестов 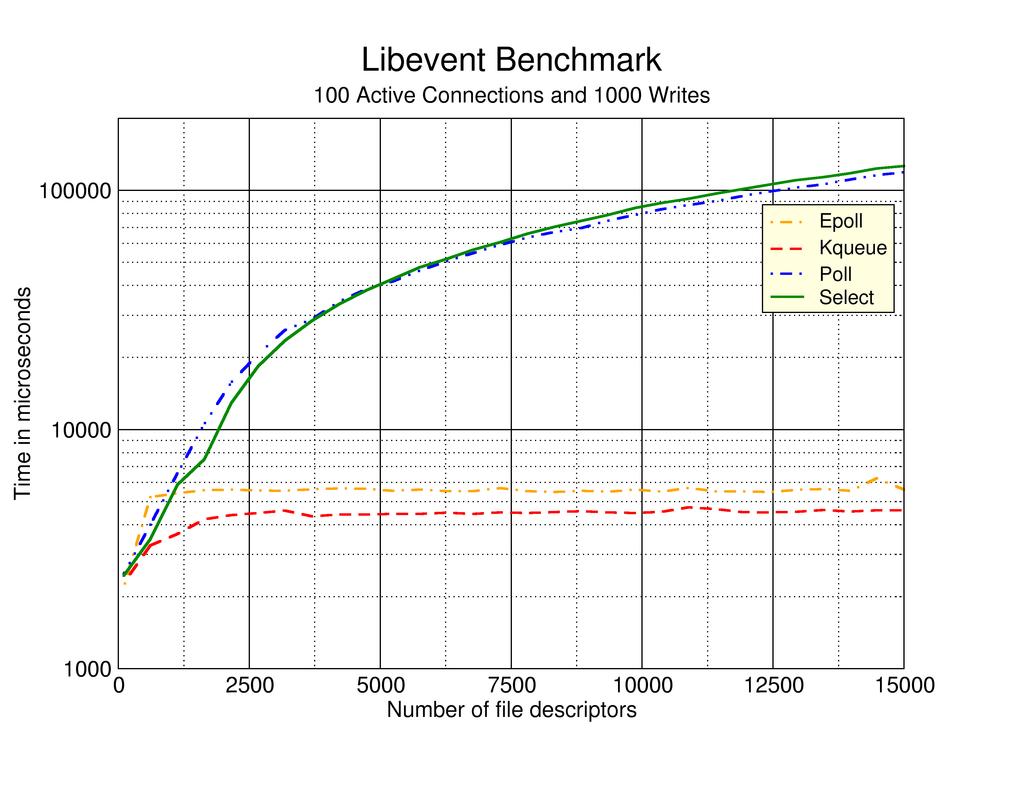 .
.
Кроме того, о каком количестве розеток вы говорите? Ваш подход, вероятно, не будет иметь большого значения, пока вы не начнете приобретать хотя бы несколько сотен сокетов.
Говоря о моем опыте работы с большими IRC-серверами, мы использовали select () и poll () (потому что epoll () / kqueue () были недоступны). При примерно 700 одновременных клиентах сервер будет использовать 100% ЦП (сервер irc не был многопоточным). Однако, что интересно, сервер все равно будет работать хорошо. Приблизительно при 4000 клиентов сервер начинал отставать.
Причина этого заключалась в том, что примерно у 700 клиентов, когда мы вернемся к select (), будет один клиент, доступный для обработки. Сканирование циклов for (), чтобы выяснить, какой это был клиент, будет поглощать большую часть ЦП. По мере того, как у нас появляется больше клиентов, мы начинаем получать все больше и больше клиентов, нуждающихся в обработке при каждом вызове select (), поэтому мы становимся более эффективными.
Переходя к epoll () / kqueue (), машины с аналогичной спецификацией будут тривиально иметь дело с 10 000 клиентов, причем некоторые (правда, более мощные машины, но все же машины, которые по сегодняшним меркам будут считаться крошечными), обслуживали 30 000 клиентов, не нарушая пот.
Эксперименты, которые я видел с SIGIO, похоже, показывают, что он хорошо работает для приложений, где задержка чрезвычайно важна, где всего несколько активных клиентов выполняют очень небольшую индивидуальную работу.
Я бы рекомендовал использовать epoll () / kqueue () вместо select () / poll () практически в любой ситуации. Я не экспериментировал с разделением клиентов между потоками. Честно говоря, я никогда не находил сервис, который требовал бы дополнительной работы по оптимизации клиентской обработки переднего плана, чтобы оправдать эксперименты с потоками.
Я провел два последних года, работая над этой конкретной проблемой (для веб-сервера G-WAN, который поставляется с МНОГИМИ тестами и диаграммами, раскрывающими все это).
Модель, которая лучше всего работает в Linux, - это epoll с одной очередью событий (и, для тяжелой обработки, несколькими рабочими потоками).
Если у вас небольшая обработка (низкая задержка обработки), тогда использование одного потока будет быстрее при использовании нескольких потоков.
Причина этого в том, что epoll не масштабируется на многоядерных процессорах (использование нескольких параллельных очередей epoll для ввода-вывода подключения в одном и том же приложении пользовательского режима только замедлит ваш сервер).
Я не смотрел серьезно на код epoll в ядре (пока я сосредоточился только на пользовательском режиме), но я предполагаю, что реализация epoll в ядре повреждена блокировками.
Вот почему использование нескольких ниток быстро ударит по стене.
Само собой разумеется, что такое плохое положение вещей не должно длиться долго, если Linux хочет сохранить свои позиции как одно из наиболее производительных ядер.
Думаю, это решенная проблема и ответ здесь - kegel.com/c10k.html