Хотите сохранить двоичное дерево на диск для игры «20 вопросов»
Короче говоря, я хотел бы изучить / разработать элегантный метод сохранения двоичного дерева на диск (общее дерево, не обязательно BST). Вот описание моей проблемы:
Реализую игру «20 вопросов». Я написал двоичное дерево, внутренними узлами которого являются вопросы, а листьями - ответы. Левый дочерний элемент узла - это путь, по которому вы пошли бы, если бы кто-то ответил «да» на ваш текущий вопрос, а правый дочерний элемент - это ответ «нет». Обратите внимание, что это не двоичное дерево поиск, а просто двоичное дерево, левый дочерний элемент которого - «да», а правый - «нет».
Программа добавляет узел к дереву, если встречает нулевой лист, прося пользователя отличить ее ответ от того, о котором думал компьютер.
Это удобно, потому что дерево выстраивается по мере того, как пользователь играет. Что неприятно, так это то, что у меня нет хорошего способа сохранить дерево на диск.
Я думал о сохранении дерева как представления массива (для узла i левый дочерний элемент равен 2i + 1, а 2i + 2 справа, (i-1) / 2 для родительского), но оно не чистое, и я получаю много потраченного впустую места.
Есть ли идеи для элегантного решения для сохранения разреженного двоичного дерева на диск?




Ответы 8
Я бы сделал обход уровня. То есть вы в основном используете алгоритм Поиск в ширину.
У тебя есть:
- Создайте очередь со вставленным в нее корневым элементом
- Удалите элемент из очереди, назовите его E
- Добавьте в очередь левого и правого потомков E. Если нет левого или правого, просто поместите представление нулевого узла.
- записать узел E на диск.
- Повторите, начиная с шага 2.
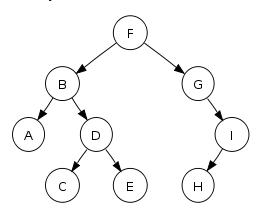
Последовательность обхода в порядке уровней: F, B, G, A, D, I, C, E, H
Что вы будете хранить на диске: F, B, G, A, D, NullNode, I, NullNode, NullNode, C, E, H, NullNode
Загрузить его обратно с диска еще проще. Просто прочтите слева направо узлы, которые вы сохранили на диске. Это даст вам левый и правый узлы каждого уровня. Т.е. дерево заполнится сверху вниз слева направо.
Шаг 1:
F
Шаг 2:
F
B
Шаг 3 чтение:
F
B G
Шаг 4 чтение:
F
B G
A
И так далее ...
Примечание: как только у вас есть представление узла NULL, вам больше не нужно перечислять его дочерние элементы на диск. При обратной загрузке вы будете знать, что нужно перейти к следующему узлу. Так что для очень глубоких деревьев это решение по-прежнему будет эффективным.
Когда вы загружаете его обратно с диска, как подключить потомков к родительскому узлу?
На самом деле загрузка - это НЕ просто. Нам все еще нужна очередь, чтобы запомнить родителей верхнего уровня ... и затем подключить их соответствующих потомков.
Простой способ сделать это - пройти по дереву, выводя каждый элемент по мере того, как вы это делаете. Затем, чтобы загрузить дерево обратно, просто выполните итерацию по списку, вставляя каждый элемент обратно в дерево. Если ваше дерево не самобалансируется, вы можете переупорядочить список таким образом, чтобы окончательное дерево было достаточно сбалансированным.
Самые простые решения обычно лучше :) также может помочь сериализация
Хорошая идея, но это не сработает, если дерево не является двоичным деревом поиска (как узнать, куда вставить следующий элемент?)
Когда вы строите дерево, вы знаете, куда его вставить, поэтому считывать его обратно - то же самое. Я почти предложил то же, что и тонкий ответ, но без кода.
Я вижу, если бы была информация о том, где заканчивается каждый уровень, вы бы знали. Ваш комментарий о балансировке сбил меня с толку и заставил подумать, что вы говорите о вставке BST.
Что ж, если это BST, то чтение их в любом порядке, который вы прошли, вероятно, приведет к несбалансированному дереву, поэтому я упомянул об этом. В вопросе упоминалось «двоичное дерево», поэтому я предположил, что балансировка может быть проблемой. Как вам это удалось в итоге? Мне было бы интересно узнать.
Я бы хранил дерево так:
<node identifier>
node data
[<yes child identfier>
yes child]
[<no child identifier>
no child]
<end of node identifier>
где дочерние узлы - это просто рекурсивные экземпляры вышеперечисленного. Биты в [] являются необязательными, а четыре идентификатора являются просто константами / значениями перечисления.
Вы можете сохранить его рекурсивно:
void encodeState(OutputStream out,Node n) {
if (n==null) {
out.write("[null]");
} else {
out.write("{");
out.write(n.nodeDetails());
encodeState(out, n.yesNode());
encodeState(out, n.noNode());
out.write("}");
}
}
Разработайте свой собственный менее текстовый формат вывода. Я уверен, что мне не нужно описывать метод чтения результирующего вывода.
Это обход в глубину. В ширину тоже работает.
Точнее, это обход предварительного заказа. [Knuth, т. 1], что еще?
Самый произвольный простой способ - это просто базовый формат, который можно использовать для представления любого графа.
<parent>,<relation>,<child>
Т.е.:
"Is it Red", "yes", "does it have wings"
"Is it Red", "no" , "does it swim"
Здесь нет избыточности много, и форматы в основном удобочитаемы, единственное дублирование данных заключается в том, что для каждого прямого дочернего элемента должна быть копия родителя.
Единственное, на что вам действительно стоит обратить внимание, это то, что вы случайно не сгенерируете цикл;)
Если только вы этого не хотите.
The problem here is rebuilding the tree afterwards. If I create the "does it have wings" object upon reading the first line, I have to somehow locate it when I later encounter the line reading "does it have wings","yes","Has it got a beak?"
Вот почему я традиционно просто использую графические структуры в памяти для таких вещей с указателями, идущими повсюду.
[0x1111111 "Is It Red" => [ 'yes' => 0xF752347 , 'no' => 0xFF6F664 ],
0xF752347 "does it have wings" => [ 'yes' => 0xFFFFFFF , 'no' => 0x2222222 ],
0xFF6F664 "does it swim" => [ 'yes' => "I Dont KNOW :( " , ... etc etc ]
Тогда связь «дочерний / родительский» - это просто метаданные.
Проблема здесь в том, чтобы потом перестроить дерево. Если я создаю объект «есть ли у него крылья» после прочтения первой строки, мне нужно как-то найти его, когда я позже встречу строку, читающую «есть ли у него крылья», «да», «у него есть клюв?»
Не уверен, что это элегантно, но все просто и объяснимо: Назначьте уникальный идентификатор каждому узлу, будь то ствол или лист. Подойдет простое счетное целое число.
При сохранении на диск просмотрите дерево, сохраняя идентификатор каждого узла, идентификатор ссылки «да», идентификатор ссылки «нет» и текст вопроса или ответа. Для пустых ссылок используйте ноль в качестве нулевого значения. Вы можете либо добавить флаг, чтобы указать, вопрос или ответ, или, проще говоря, проверить, являются ли обе ссылки нулевыми. У вас должно получиться что-то вроде этого:
1,2,3,"Does it have wings?"
2,0,0,"a bird"
3,4,0,"Does it purr?"
4,0,0,"a cat"
Обратите внимание, что если вы используете подход с последовательными целыми числами, сохранение идентификатора узла может быть избыточным, как показано здесь. Вы можете просто упорядочить их по идентификатору.
Для восстановления с диска прочтите строку, затем добавьте ее в дерево. Вам, вероятно, понадобится таблица или массив для хранения узлов с прямой ссылкой, например при обработке узла 1 вам нужно будет отслеживать 2 и 3, пока вы не заполните эти значения.
В java, если вы должны сделать класс сериализуемым, вы можете просто записать объект класса на диск и прочитать его, используя потоки ввода / вывода.
Вот код C++ с использованием PreOrder DFS:
void SaveBinaryTreeToStream(TreeNode* root, ostringstream& oss)
{
if (!root)
{
oss << '#';
return;
}
oss << root->data;
SaveBinaryTreeToStream(root->left, oss);
SaveBinaryTreeToStream(root->right, oss);
}
TreeNode* LoadBinaryTreeFromStream(istringstream& iss)
{
if (iss.eof())
return NULL;
char c;
if ('#' == (c = iss.get()))
return NULL;
TreeNode* root = new TreeNode(c, NULL, NULL);
root->left = LoadBinaryTreeFromStream(iss);
root->right = LoadBinaryTreeFromStream(iss);
return root;
}
В main() вы можете:
ostringstream oss;
root = MakeCharTree();
PrintVTree(root);
SaveBinaryTreeToStream(root, oss);
ClearTree(root);
cout << oss.str() << endl;
istringstream iss(oss.str());
cout << iss.str() << endl;
root = LoadBinaryTreeFromStream(iss);
PrintVTree(root);
ClearTree(root);
/* Output:
A
B C
D E F
G H I
ABD#G###CEH##I##F##
ABD#G###CEH##I##F##
A
B C
D E F
G H I
*/
DFS легче понять.
*********************************************************************************
Но мы можем использовать сканирование уровня BFS, используя очередь
ostringstream SaveBinaryTreeToStream_BFS(TreeNode* root)
{
ostringstream oss;
if (!root)
return oss;
queue<TreeNode*> q;
q.push(root);
while (!q.empty())
{
TreeNode* tn = q.front(); q.pop();
if (tn)
{
q.push(tn->left);
q.push(tn->right);
oss << tn->data;
}
else
{
oss << '#';
}
}
return oss;
}
TreeNode* LoadBinaryTreeFromStream_BFS(istringstream& iss)
{
if (iss.eof())
return NULL;
TreeNode* root = new TreeNode(iss.get(), NULL, NULL);
queue<TreeNode*> q; q.push(root); // The parents from upper level
while (!iss.eof() && !q.empty())
{
TreeNode* tn = q.front(); q.pop();
char c = iss.get();
if ('#' == c)
tn->left = NULL;
else
q.push(tn->left = new TreeNode(c, NULL, NULL));
c = iss.get();
if ('#' == c)
tn->right = NULL;
else
q.push(tn->right = new TreeNode(c, NULL, NULL));
}
return root;
}
В main() вы можете:
root = MakeCharTree();
PrintVTree(root);
ostringstream oss = SaveBinaryTreeToStream_BFS(root);
ClearTree(root);
cout << oss.str() << endl;
istringstream iss(oss.str());
cout << iss.str() << endl;
root = LoadBinaryTreeFromStream_BFS(iss);
PrintVTree(root);
ClearTree(root);
/* Output:
A
B C
D E F
G H I
ABCD#EF#GHI########
ABCD#EF#GHI########
A
B C
D E F
G H I
*/
Думаю, вы также можете обрезать все NullNodes с конца. По какой-то причине вы обрезали все, кроме 1.