Сглаживание мелкого списка в Python
Есть ли простой способ сгладить список итераций с помощью понимания списка, или, если это не удается, что вы все считаете лучшим способом сгладить такой неглубокий список, уравновешивая производительность и удобочитаемость?
Я попытался сгладить такой список с помощью вложенного списка, например:
[image for image in menuitem for menuitem in list_of_menuitems]
Но у меня там проблемы с разновидностью NameError, потому что name 'menuitem' is not defined. После поиска в Google и просмотра Stack Overflow я получил желаемые результаты с помощью оператора reduce:
reduce(list.__add__, map(lambda x: list(x), list_of_menuitems))
Но этот метод практически не читается, потому что мне нужен этот вызов list(x), потому что x - это объект Django QuerySet.
Заключение:
Спасибо всем, кто внес свой вклад в этот вопрос. Вот краткое изложение того, что я узнал. Я также делаю это вики сообщества на случай, если другие захотят дополнить или исправить эти наблюдения.
Моя первоначальная инструкция сокращения избыточна и лучше написана так:
>>> reduce(list.__add__, (list(mi) for mi in list_of_menuitems))
Это правильный синтаксис для понимания вложенного списка (блестящее резюме dF!):
>>> [image for mi in list_of_menuitems for image in mi]
Но ни один из этих методов не так эффективен, как использование itertools.chain:
>>> from itertools import chain
>>> list(chain(*list_of_menuitems))
И, как отмечает @cdleary, вероятно, лучше избегать магии оператора *, используя chain.from_iterable следующим образом:
>>> chain = itertools.chain.from_iterable([[1,2],[3],[5,89],[],[6]])
>>> print(list(chain))
>>> [1, 2, 3, 5, 89, 6]
Это эквивалентно. К счастью, Prairie Dogg осознал, что этот код уродлив. :)
О да, я вижу, что вы указали на это в своем ответе @recursive. Извините за избыточность! :-)
@recursive: Да, я определенно покраснел после того, как вы указали, сколько вещей в моем операторе сокращения было лишним. Я определенно многому научился из этого вопроса, большое спасибо всем!
Я уже некоторое время изучаю Ruby и только что имел возможность использовать идиому Ruby для аналогичной проблемы. FWIW: [[1,2], [3], [5,89], [], [6]]. Flatten -> [1, 2, 3, 5, 89, 6]
reduce (list .__ add__, (list (mi.image_set.all ()) для mi в list_of_menuitems)) неверно для случая, когда все списки пусты. Его следует уменьшить (list .__ add__, (list (mi.image_set.all ()) для mi в list_of_menuitems), [])
Этот вопрос закрыл stackoverflow.com/q/952914/1206998 как дублированный. Однако это гораздо менее понятно из-за всего, что не имеет отношения к django. Следует ли его переписать?






Ответы 23
Вне всяких сомнений, вы можете исключить лямбду:
reduce(list.__add__, map(list, [mi.image_set.all() for mi in list_of_menuitems]))
Или даже удалите карту, так как у вас уже есть список:
reduce(list.__add__, [list(mi.image_set.all()) for mi in list_of_menuitems])
Вы также можете просто выразить это как сумму списков:
sum([list(mi.image_set.all()) for mi in list_of_menuitems], [])
Вы можете просто использовать add, и я считаю, что второй аргумент суммы излишен.
Это не лишнее. По умолчанию значение равно нулю, что приводит к TypeError: неподдерживаемый тип (ы) операндов для +: 'int' и 'list'. IMO sum () более прямая, чем reduce (add, ...)
Как насчет:
from operator import add
reduce(add, map(lambda x: list(x.image_set.all()), [mi for mi in list_of_menuitems]))
Но Гвидо не рекомендует выполнять слишком много работы в одной строке кода, поскольку это снижает удобочитаемость. Прирост производительности минимальный, если он вообще есть, за счет выполнения желаемого в одной строке по сравнению с несколькими строками.
Это невероятно приятно выполнять какой-то сумасшедший объем работы в одной строке ... но на самом деле это просто синтаксический suger
Если я правильно помню, Гвидо на самом деле также не рекомендует использовать сокращения и понимание списков ... Я не согласен, хотя они невероятно полезны.
Сравните производительность этого маленького самородка с многострочной функцией. Думаю, вы обнаружите, что эта строчка - настоящая собака.
возможно, отображение с лямбдами - это ужасно. накладные расходы, возникающие при каждом вызове функции, высасывают жизнь из вашего кода. Я никогда не говорил, что эта конкретная строка была такой же быстрой, как многострочное решение ...;)
Если вы просто хотите перебрать плоскую версию структуры данных и вам не нужна индексируемая последовательность, рассмотрите itertools.chain и компания.
>>> list_of_menuitems = [['image00', 'image01'], ['image10'], []]
>>> import itertools
>>> chain = itertools.chain(*list_of_menuitems)
>>> print(list(chain))
['image00', 'image01', 'image10']
Он будет работать со всем, что можно итерировать, включая повторяющиеся QuerySet от Django, которые, похоже, вы используете в вопросе.
Редактировать: В любом случае это, вероятно, так же хорошо, как и сокращение, потому что сокращение будет иметь такие же накладные расходы при копировании элементов в расширяемый список. chain будет нести эти (те же) накладные расходы, только если вы запустите list(chain) в конце.
Мета-редактирование: На самом деле, это меньше накладных расходов, чем предлагаемое решение вопроса, потому что вы отбрасываете временные списки, которые создаете, когда расширяете оригинал временным.
Редактировать: Поскольку J.F. Себастьян говоритitertools.chain.from_iterable избегает распаковки, вы должны использовать это, чтобы избежать магии *, но приложение timeit показывает незначительную разницу в производительности.
Явный цикл, использующий Метод .extend - самое быстрое решение согласно этому тесту
не слышал от from_iterable. он красивее, чем *, если менее питонический
Также стоит подчеркнуть, что, поскольку from_iterable избегает распаковки, он может избежать проблем, когда у вас есть много (потенциально неограниченных) элементов в итерируемом объекте. Если итерация достаточно длинная, у вас закончится память.
Вот правильное решение, использующее понимание списков (они заданы в вопросе):
>>> join = lambda it: (y for x in it for y in x)
>>> list(join([[1,2],[3,4,5],[]]))
[1, 2, 3, 4, 5]
В вашем случае это было бы
[image for menuitem in list_of_menuitems for image in menuitem.image_set.all()]
или вы можете использовать join и сказать
join(menuitem.image_set.all() for menuitem in list_of_menuitems)
В любом случае, проблема заключалась во вложении петель for.
Вы почти получили это! способ сделать понимание вложенных списков предназначен для размещения операторов for в том же порядке, что и в обычных вложенных операторах for.
Таким образом, это
for inner_list in outer_list:
for item in inner_list:
...
соответствует
[... for inner_list in outer_list for item in inner_list]
Так ты хочешь
[image for menuitem in list_of_menuitems for image in menuitem]
+1, я смотрел это так много раз, и это единственный ответ, который я видел, что делает упорядочение явным ... Может быть, теперь я могу это вспомнить!
Я хотел бы проголосовать за это снова, потому что такой образ мышления значительно упрощает понимание вложенных списков.
тогда как [... for item in inner_list для inner_list в outer_list] - это ошибка Python: он повторяет [... for item in inner_list] только для последнего значения inner_list и столько раз, сколько len (external_list). Бесполезный.
Этот порядок В самом деле нечетный. Если вы измените for i in list: ... на ... for i in list, то почему бы вам также не изменить порядок циклов for?
Лучшее объяснение вложенных списков, которые я нашел даже после прочтения документации. Комментирую, чтобы я мог найти это позже.
Да, старый пост, но лучшее простое объяснение вложенных понятий. Спасибо ... Все еще неловко, когда поток возвращается на передний план, но теперь это имеет смысл.
"в том же порядке, в каком они идут в обычных вложенных операторах for" - это очень ясный способ выразить это. Теперь я не забуду этого снова.
Ха! Я снова забыл об этом. Я полагаю, что мозг Гвидо и мой просто расходятся во мнениях относительно того, что интуитивно понятно.
Результаты производительности. Пересмотрено.
import itertools
def itertools_flatten( aList ):
return list( itertools.chain(*aList) )
from operator import add
def reduce_flatten1( aList ):
return reduce(add, map(lambda x: list(x), [mi for mi in aList]))
def reduce_flatten2( aList ):
return reduce(list.__add__, map(list, aList))
def comprehension_flatten( aList ):
return list(y for x in aList for y in x)
Я выровнял двухуровневый список из 30 пунктов 1000 раз
itertools_flatten 0.00554
comprehension_flatten 0.00815
reduce_flatten2 0.01103
reduce_flatten1 0.01404
Уменьшить - всегда плохой выбор.
map(lambda x: list(x), [mi for mi in aList])) - это map(list, aList).
reduce_flatten = lambda list_of_iters: reduce(list.__add__, map(list, list_of_iters))itertools_flatten2 = lambda aList: list(itertools.chain.from_iterable(aList))В 2.5.2 нет chain.from_iterable - извините - не может сравниться с другими решениями.
@ рекурсивная версия: sum_flatten = lambda aList: sum(map(list, aList), [])
Это решение работает для произвольной глубины вложенности, а не только для глубины «списка списков», которой некоторые (все?) Другие решения ограничены:
def flatten(x):
result = []
for el in x:
if hasattr(el, "__iter__") and not isinstance(el, basestring):
result.extend(flatten(el))
else:
result.append(el)
return result
Это рекурсия, которая допускает произвольную глубину вложения - до тех пор, пока вы не достигнете максимальной глубины рекурсии, конечно ...
Возможно, стоит добавить hasattr(el, '__getitem__') для совместимости с функцией iter() и встроенным циклом for-in (хотя все последовательности Python (объекты с __getitem__) также являются итеративными (объект с __iter__)).
я ожидал чего-то подобного уже в itertools. есть ли аналогичные решения с использованием понимания?
Это было для меня наиболее полезным, поскольку не разделяет строки.
@JosepVallsm хорошее решение! для python3 вам нужно использовать str вместо basestring, Встроенный абстрактный тип basestring был удален. Вместо этого используйте str. Типы str и bytes не обладают достаточной общей функциональностью, чтобы гарантировать общий базовый класс. Инструмент 2to3 (см. Ниже) заменяет каждое вхождение basestring на str.
@JosepValls, также, не могли бы вы сказать, почему аналогичный метод, подобный твоему дает вход RECURSION ERROR ONA = ['str1', [[[['str2']]]], [['str3'], 'str4'], 'str5'] and input A = [1.0, 2, 'a', (4,), ((6,), (8,)), (((8,) , (9,)), ((12,), (10)))] `, но с вашим решением работать нормально!
@ S.Lott: Вы вдохновили меня написать приложение timeit.
Я подумал, что это также будет зависеть от количества разделов (количества итераторов в списке контейнеров) - в вашем комментарии не упоминалось, сколько разделов было из тридцати элементов. Этот сюжет сглаживает тысячу элементов за каждый прогон с различным количеством разделов. Предметы равномерно распределяются по перегородкам.
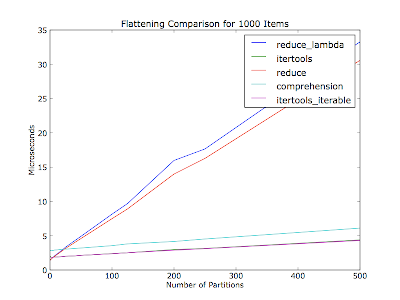
Код (Python 2.6):
#!/usr/bin/env python2.6
"""Usage: %prog item_count"""
from __future__ import print_function
import collections
import itertools
import operator
from timeit import Timer
import sys
import matplotlib.pyplot as pyplot
def itertools_flatten(iter_lst):
return list(itertools.chain(*iter_lst))
def itertools_iterable_flatten(iter_iter):
return list(itertools.chain.from_iterable(iter_iter))
def reduce_flatten(iter_lst):
return reduce(operator.add, map(list, iter_lst))
def reduce_lambda_flatten(iter_lst):
return reduce(operator.add, map(lambda x: list(x), [i for i in iter_lst]))
def comprehension_flatten(iter_lst):
return list(item for iter_ in iter_lst for item in iter_)
METHODS = ['itertools', 'itertools_iterable', 'reduce', 'reduce_lambda',
'comprehension']
def _time_test_assert(iter_lst):
"""Make sure all methods produce an equivalent value.
:raise AssertionError: On any non-equivalent value."""
callables = (globals()[method + '_flatten'] for method in METHODS)
results = [callable(iter_lst) for callable in callables]
if not all(result == results[0] for result in results[1:]):
raise AssertionError
def time_test(partition_count, item_count_per_partition, test_count=10000):
"""Run flatten methods on a list of :param:`partition_count` iterables.
Normalize results over :param:`test_count` runs.
:return: Mapping from method to (normalized) microseconds per pass.
"""
iter_lst = [[dict()] * item_count_per_partition] * partition_count
print('Partition count: ', partition_count)
print('Items per partition:', item_count_per_partition)
_time_test_assert(iter_lst)
test_str = 'flatten(%r)' % iter_lst
result_by_method = {}
for method in METHODS:
setup_str = 'from test import %s_flatten as flatten' % method
t = Timer(test_str, setup_str)
per_pass = test_count * t.timeit(number=test_count) / test_count
print('%20s: %.2f usec/pass' % (method, per_pass))
result_by_method[method] = per_pass
return result_by_method
if __name__ == '__main__':
if len(sys.argv) != 2:
raise ValueError('Need a number of items to flatten')
item_count = int(sys.argv[1])
partition_counts = []
pass_times_by_method = collections.defaultdict(list)
for partition_count in xrange(1, item_count):
if item_count % partition_count != 0:
continue
items_per_partition = item_count / partition_count
result_by_method = time_test(partition_count, items_per_partition)
partition_counts.append(partition_count)
for method, result in result_by_method.iteritems():
pass_times_by_method[method].append(result)
for method, pass_times in pass_times_by_method.iteritems():
pyplot.plot(partition_counts, pass_times, label=method)
pyplot.legend()
pyplot.title('Flattening Comparison for %d Items' % item_count)
pyplot.xlabel('Number of Partitions')
pyplot.ylabel('Microseconds')
pyplot.show()
Редактировать: Решил сделать это вики сообщества.
Примечание:METHODS, вероятно, следует накапливать с помощью декоратора, но я полагаю, что людям будет легче читать таким образом.
Попробуйте sum_flatten = lambda iter_lst: sum(map(list, iter_lst), [])
или просто сумма (список, [])
@EnTerr предложил reduce(operator.iaddstackoverflow.com/questions/3040335/…, который на данный момент является самым быстрым (код: ideone.com/NWThp изображение: i403.photobucket.com/albums/pp111/uber_ulrich/p1000.png)
chain.from_iterable() немного быстрее, если много разделов i403.photobucket.com/albums/pp111/uber_ulrich/p10000.pngЯ знаю, что это старый поток, но я добавил метод, полученный от здесь, который использует list.extend, который показал себя самым быстрым по всем направлениям. графикобновленная суть
В Python 3.4 вы сможете:
[*innerlist for innerlist in outer_list]
Хм. Хотя я бы приветствовал это, это уже обсуждалось еще для Py3.0. Теперь PEP 448 присутствует, но все еще находится в режиме «Черновик». Соответствующий билет об ошибке все еще находится в «обзоре исправлений» с еще неполным исправлением. До тех пор, пока ошибка не будет помечена как «совершенная», я буду осторожен, надеясь и сказав: «Вы сможете это сделать».
Я понимаю, что вы имеете в виду, но недавно один из основных разработчиков объявил об этом на Kiwi PyCon 2013 как о «принятом к выпуску» в версии 3.4. Все еще не уверен на 100%, но полагаю, что весьма вероятно.
Будем надеяться, что это просто нехватка документации за кодом, как обычно для sw перед выпуском ;-)
SyntaxError: can use starred expression only as assignment targetЭтот синтаксис был не принято в окончательном PEP 448.
ты пробовал сгладить? От matplotlib.cbook.flatten (seq, скаляр =)?
l=[[1,2,3],[4,5,6], [7], [8,9]]*33
run("list(flatten(l))")
3732 function calls (3303 primitive calls) in 0.007 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.007 0.007 <string>:1(<module>)
429 0.001 0.000 0.001 0.000 cbook.py:475(iterable)
429 0.002 0.000 0.003 0.000 cbook.py:484(is_string_like)
429 0.002 0.000 0.006 0.000 cbook.py:565(is_scalar_or_string)
727/298 0.001 0.000 0.007 0.000 cbook.py:605(flatten)
429 0.000 0.000 0.001 0.000 core.py:5641(isMaskedArray)
858 0.001 0.000 0.001 0.000 {isinstance}
429 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*66
run("list(flatten(l))")
7461 function calls (6603 primitive calls) in 0.007 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.007 0.007 <string>:1(<module>)
858 0.001 0.000 0.001 0.000 cbook.py:475(iterable)
858 0.002 0.000 0.003 0.000 cbook.py:484(is_string_like)
858 0.002 0.000 0.006 0.000 cbook.py:565(is_scalar_or_string)
1453/595 0.001 0.000 0.007 0.000 cbook.py:605(flatten)
858 0.000 0.000 0.001 0.000 core.py:5641(isMaskedArray)
1716 0.001 0.000 0.001 0.000 {isinstance}
858 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*99
run("list(flatten(l))")
11190 function calls (9903 primitive calls) in 0.010 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.010 0.010 <string>:1(<module>)
1287 0.002 0.000 0.002 0.000 cbook.py:475(iterable)
1287 0.003 0.000 0.004 0.000 cbook.py:484(is_string_like)
1287 0.002 0.000 0.009 0.000 cbook.py:565(is_scalar_or_string)
2179/892 0.001 0.000 0.010 0.000 cbook.py:605(flatten)
1287 0.001 0.000 0.001 0.000 core.py:5641(isMaskedArray)
2574 0.001 0.000 0.001 0.000 {isinstance}
1287 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*132
run("list(flatten(l))")
14919 function calls (13203 primitive calls) in 0.013 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.013 0.013 <string>:1(<module>)
1716 0.002 0.000 0.002 0.000 cbook.py:475(iterable)
1716 0.004 0.000 0.006 0.000 cbook.py:484(is_string_like)
1716 0.003 0.000 0.011 0.000 cbook.py:565(is_scalar_or_string)
2905/1189 0.002 0.000 0.013 0.000 cbook.py:605(flatten)
1716 0.001 0.000 0.001 0.000 core.py:5641(isMaskedArray)
3432 0.001 0.000 0.001 0.000 {isinstance}
1716 0.001 0.000 0.001 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler'
ОБНОВИТЬ Это дало мне еще одну идею:
l=[[1,2,3],[4,5,6], [7], [8,9]]*33
run("flattenlist(l)")
564 function calls (432 primitive calls) in 0.000 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
133/1 0.000 0.000 0.000 0.000 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
429 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*66
run("flattenlist(l)")
1125 function calls (861 primitive calls) in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
265/1 0.001 0.000 0.001 0.001 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
858 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*99
run("flattenlist(l)")
1686 function calls (1290 primitive calls) in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
397/1 0.001 0.000 0.001 0.001 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
1287 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*132
run("flattenlist(l)")
2247 function calls (1719 primitive calls) in 0.002 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
529/1 0.001 0.000 0.002 0.002 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.002 0.002 <string>:1(<module>)
1716 0.001 0.000 0.001 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*1320
run("flattenlist(l)")
22443 function calls (17163 primitive calls) in 0.016 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
5281/1 0.011 0.000 0.016 0.016 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.016 0.016 <string>:1(<module>)
17160 0.005 0.000 0.005 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
Итак, чтобы проверить, насколько это эффективно, когда рекурсивная становится глубже: насколько глубже?
l=[[1,2,3],[4,5,6], [7], [8,9]]*1320
new=[l]*33
run("flattenlist(new)")
740589 function calls (566316 primitive calls) in 0.418 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
174274/1 0.281 0.000 0.417 0.417 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.001 0.001 0.418 0.418 <string>:1(<module>)
566313 0.136 0.000 0.136 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*66
run("flattenlist(new)")
1481175 function calls (1132629 primitive calls) in 0.809 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
348547/1 0.542 0.000 0.807 0.807 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.002 0.002 0.809 0.809 <string>:1(<module>)
1132626 0.266 0.000 0.266 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*99
run("flattenlist(new)")
2221761 function calls (1698942 primitive calls) in 1.211 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
522820/1 0.815 0.000 1.208 1.208 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.002 0.002 1.211 1.211 <string>:1(<module>)
1698939 0.393 0.000 0.393 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*132
run("flattenlist(new)")
2962347 function calls (2265255 primitive calls) in 1.630 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
697093/1 1.091 0.000 1.627 1.627 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.003 0.003 1.630 1.630 <string>:1(<module>)
2265252 0.536 0.000 0.536 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*1320
run("flattenlist(new)")
29623443 function calls (22652523 primitive calls) in 16.103 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
6970921/1 10.842 0.000 16.069 16.069 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.034 0.034 16.103 16.103 <string>:1(<module>)
22652520 5.227 0.000 5.227 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
Готов поспорить на "flattenlist". Я собираюсь использовать это вместо matploblib в течение долгого времени, если мне не нужен генератор доходности и быстрый результат, как "flatten" в matploblib.cbook
Это быстро.
- А вот код
:
typ=(list,tuple)
def flattenlist(d):
thelist = []
for x in d:
if not isinstance(x,typ):
thelist += [x]
else:
thelist += flattenlist(x)
return thelist
Эта версия является генератором. Подправьте его, если хотите список.
def list_or_tuple(l):
return isinstance(l,(list,tuple))
## predicate will select the container to be flattened
## write your own as required
## this one flattens every list/tuple
def flatten(seq,predicate=list_or_tuple):
## recursive generator
for i in seq:
if predicate(seq):
for j in flatten(i):
yield j
else:
yield i
Вы можете добавить предикат, если хотите сгладить те, которые удовлетворяют условию
Взято из кулинарной книги Python
По моему опыту, наиболее эффективный способ сгладить список списков:
flat_list = []
map(flat_list.extend, list_of_list)
Некоторое время его сравнения с другими предложенными методами:
list_of_list = [range(10)]*1000
%timeit flat_list=[]; map(flat_list.extend, list_of_list)
#10000 loops, best of 3: 119 µs per loop
%timeit flat_list=list(itertools.chain.from_iterable(list_of_list))
#1000 loops, best of 3: 210 µs per loop
%timeit flat_list=[i for sublist in list_of_list for i in sublist]
#1000 loops, best of 3: 525 µs per loop
%timeit flat_list=reduce(list.__add__,list_of_list)
#100 loops, best of 3: 18.1 ms per loop
Теперь при обработке более длинных подсписок повышение эффективности выглядит лучше:
list_of_list = [range(1000)]*10
%timeit flat_list=[]; map(flat_list.extend, list_of_list)
#10000 loops, best of 3: 60.7 µs per loop
%timeit flat_list=list(itertools.chain.from_iterable(list_of_list))
#10000 loops, best of 3: 176 µs per loop
И эти методы также работают с любым итеративным объектом:
class SquaredRange(object):
def __init__(self, n):
self.range = range(n)
def __iter__(self):
for i in self.range:
yield i**2
list_of_list = [SquaredRange(5)]*3
flat_list = []
map(flat_list.extend, list_of_list)
print flat_list
#[0, 1, 4, 9, 16, 0, 1, 4, 9, 16, 0, 1, 4, 9, 16]
pylab обеспечивает сглаживание: ссылка на numpy flatten
Примечание: Flatten не работает с зубчатыми массивами. Попробуйте вместо этого использовать стек.
sum(list_of_lists, []) сгладил бы его.
l = [['image00', 'image01'], ['image10'], []]
print sum(l,[]) # prints ['image00', 'image01', 'image10']
Мне это нравится! Это напоминает мне использование iter[::-1] вместо sorted(iter, reverse=True). Интересно, будет ли это одной из тех вещей, которые с годами будут рассматривать как «плохой Python». Мне это кажется очень подходящим для TIMTOWTDI.
Вроде бы путаница с operator.add! Когда вы складываете два списка вместе, правильный термин для этого - concat, а не добавление. operator.concat - это то, что вам нужно.
Если вы думаете о функциональности, это очень просто:
>>> list2d = ((1,2,3),(4,5,6), (7,), (8,9))
>>> reduce(operator.concat, list2d)
(1, 2, 3, 4, 5, 6, 7, 8, 9)
Вы видите, что сокращение уважает тип последовательности, поэтому, когда вы предоставляете кортеж, вы получаете обратно кортеж. попробуем со списком:
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> reduce(operator.concat, list2d)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Ага, вы вернули список.
Как насчет производительности:
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> %timeit list(itertools.chain.from_iterable(list2d))
1000000 loops, best of 3: 1.36 µs per loop
from_iterable работает довольно быстро! Но сокращение с помощью concat - не сравнение.
>>> list2d = ((1,2,3),(4,5,6), (7,), (8,9))
>>> %timeit reduce(operator.concat, list2d)
1000000 loops, best of 3: 492 ns per loop
это, наверное, лучшее решение для одного уровня вложенности. но это может быть слишком ограничивающим ограничением. YMMV
Если каждый элемент в списке является строкой (и в любых строках внутри этих строк используется "", а не ""), вы можете использовать регулярные выражения (модуль re).
>>> flattener = re.compile("\'.*?\'")
>>> flattener
<_sre.SRE_Pattern object at 0x10d439ca8>
>>> stred = str(in_list)
>>> outed = flattener.findall(stred)
Приведенный выше код преобразует in_list в строку, использует регулярное выражение для поиска всех подстрок в кавычках (то есть каждого элемента списка) и выводит их в виде списка.
Вот версия, работающая для нескольких уровней списка с использованием collectons.Iterable:
import collections
def flatten(o, flatten_condition=lambda i: isinstance(i,
collections.Iterable) and not isinstance(i, str)):
result = []
for i in o:
if flatten_condition(i):
result.extend(flatten(i, flatten_condition))
else:
result.append(i)
return result
Не могли бы предложить, почему ваше решение дает RecursionError: maximum recursion depth exceeded in comparison на этом входе A = ['image1', [[[['image2']]]], [['image3'], 'image4'], 'image5'], в то время как он работает нормально, и снимает сглаживание этого ввода A = [1,[2,3],[4,5,[6,[7,8],9]]]
Это проблема со сплющенным состоянием. Поскольку строки являются итеративными, они сглаживаются как символы, которые сами по себе являются строками длины один, и поскольку они являются строками, снова применяется та же логика, и создается бесконечный цикл. Поэтому я создал новую версию с условием выравнивания для большего контроля.
Большой! big Спасибо за разъяснения, сейчас работает.! Я вроде как понял ваши рассуждения, но не смог полностью их переварить. Не могли бы вы указать мне на какую-нибудь статью в Интернете или любой пост, который поможет разобраться в проблеме! Я понял, что `['image1'] -> ['i', 'm', 'a', 'g', 'e', '1']` т.е. строки длины один !, и теперь, как это будет идти в бесконечном цикле, а что заставляет идти в бесконечном цикле? эту часть я еще не понял! Вы можете чем-то помочь!
Чтобы функция сглаживалась до конца, если она входит в цикл for, в какой-то момент она должна перейти в оператор else. Если он входит в оператор else, он начинает разворачивать стек вызовов и возвращать результат. Основываясь на предыдущей версии, поскольку «image1» является итеративным, то o будет равно «image1», а i будет равно «i». «i» также может повторяться, поэтому в следующем вызове o будет равно «i», в то время как i также будет равно «i». Функция будет вызвана снова, что приведет к тому же состоянию и бесконечному циклу, нарушенному только переполнением стека.
Лучше использовать yield для генерации последовательности элементов через список result. Итератор может быть вычислен лениво, а функция fn, использующая его, может потреблять последовательность по мере необходимости.
Если вам нужно сгладить более сложный список с не повторяемыми элементами или с глубиной более 2, вы можете использовать следующую функцию:
def flat_list(list_to_flat):
if not isinstance(list_to_flat, list):
yield list_to_flat
else:
for item in list_to_flat:
yield from flat_list(item)
Он вернет объект-генератор, который вы можете преобразовать в список с помощью функции list(). Обратите внимание, что синтаксис yield from доступен начиная с python3.3, но вместо этого вы можете использовать явную итерацию.
Пример:
>>> a = [1, [2, 3], [1, [2, 3, [1, [2, 3]]]]]
>>> print(list(flat_list(a)))
[1, 2, 3, 1, 2, 3, 1, 2, 3]
это решение дает RECURSION ERROR ON : входные A = ['str1', [[[['str2']]]], [['str3'], 'str4'], 'str5'] и A = [1.0, 2, 'a', [4,], [[6,], [8,]], [[[8,],[9,]], [[12,],[10]]]]. Вы знаете, почему и как это исправить?
@anu Он работал без ошибок на ваших примерах для меня (python 3.7.1). Я не уверен, почему у тебя это не работает.
Я использую python3.6, теперь я обнаружил проблему, вам нужно добавить or isinstance(list_to_flat, str) в первое условие if, поскольку оно должно защищать от строк. Ваше решение идеально подходило для ввода A = [1, [[[[2]]]], [[3], 4], 5], но не работает при использовании строк !, проводилось ли тестирование со строками в python3.7?
@anu Я тестировал его на тех же примерах, которые вы предоставили. Ваш первый пример был со строками, и он работал нормально. Первый оператор if говорит, что любой элемент, не входящий в список, должен возвращаться как есть, без сглаживания. Сюда входят и строки, никаких дополнительных условий не требуется.
о, хорошо, это может быть из-за различий в версии Python! Возможно, они выпустили некоторые обновления в 3.7.
человек! Это как раз то, что мне нужно! Большое спасибо!
Если вам нужен встроенный простой однострочник, вы можете использовать:
a = [[1, 2, 3], [4, 5, 6]
b = [i[x] for i in a for x in range(len(i))]
print b
возвращается
[1, 2, 3, 4, 5, 6]
Простая альтернатива - использовать конкатенация numpy, но он преобразует содержимое в float:
import numpy as np
print np.concatenate([[1,2],[3],[5,89],[],[6]])
# array([ 1., 2., 3., 5., 89., 6.])
print list(np.concatenate([[1,2],[3],[5,89],[],[6]]))
# [ 1., 2., 3., 5., 89., 6.]
Самый простой способ добиться этого в Python 2 или 3 - использовать библиотеку превращаться с помощью pip install morph.
Код такой:
import morph
list = [[1,2],[3],[5,89],[],[6]]
flattened_list = morph.flatten(list) # returns [1, 2, 3, 5, 89, 6]
"самый простой" - сильное слово
@cfi Предложенный вами ответ не работает в Python 2, и из комментариев не похоже, что это даже приемлемый ответ в Python 3. Библиотека морфинга - это простое решение с одной функцией, как у вас в lodash для javascript. В любом случае я отредактировал свой ответ, чтобы уточнить, что это самое простое решение, которое работает с Python 2 и 3.
Я действительно сожалею. Мой комментарий был немного ленивым, тем более, что вы указали на мой собственный комментарий к другому посту. Я хотел сказать, что «самый легкий» - это суперлятив, которого трудно достичь. Для вашего предложения требуется внешняя библиотека, которую некоторым может быть сложно установить (даже с venv и т. д.). Поскольку вопрос касается «мелких» списков и «баланса между производительностью и удобочитаемостью», ваш ответ может (!) Выиграть с точки зрения удобочитаемости. Но Вот этот выигрывает по производительности и проще в том, что не требует зависимостей.
@cfi yeah - мой подход может быть "подходом ленивого". Что касается меня, видя все эти способы сглаживания, мне захотелось просто найти быструю библиотечную команду, такую как я нашел с морфингом. В этой библиотеке хорошо то, что она намного меньше, чем numpy (мне нужно использовать файл подкачки для установки numpy на небольших экземплярах сервера). Он в основном использует функцию, которую вы описываете во втором комментарии; другой вариант заключался бы в том, чтобы я использовал это как вспомогательную функцию в моем коде. Вообще нет проблем, спасибо, что указали на варианты :).
def is_iterable(item):
return isinstance(item, list) or isinstance(item, tuple)
def flatten(items):
for i in items:
if is_iterable(item):
for m in flatten(i):
yield m
else:
yield i
Контрольная работа:
print list(flatten2([1.0, 2, 'a', (4,), ((6,), (8,)), (((8,),(9,)), ((12,),(10)))]))
Это может привести к сглаживанию строк в отдельные символы, что может быть нежелательным поведением?
Да, я не учел это условие. Спасибо.
@kopos, спасибо за ваше решение, но я получаю эту ошибку for m in flatten(i): [Previous line repeated 996 more times] RecursionError: maximum recursion depth exceeded на ваших входных A = [1.0, 2, 'a', (4,), ((6,), (8,)), (((8,),(9,)), ((12,),(10)))] и A = ['str1', [[[['str2']]]], [['str3'], 'str4'], 'str5'], но она отлично работает с этим входом A = [1, [[[[2]]]], [[3], 4], 5]. Вы знаете, в чем причина его отказа? а как исправить? какие-либо предложения?
@kopos, теперь у меня есть исправление !, вам нужно добавить еще одно условие в оператор if and not isinstance(i,str ) для защиты от строк в списке при выравнивании!
@anu: Да, это исправление работает! Но проблема в том, что мы определяем тип коллекции на основе hasattr и isinstance. Если мы знаем тип узлов сбора, fn можно настроить для него. Возможно, нам придется настроить функцию в зависимости от того, как она должна себя вести, если коллекция - это set.
@kopos, вы правы, есть способ обобщения коллекций с помощью typing.Sequence и использования Sequence вместо фиксированного типа коллекции, такого как list, strings, sets, range etc!, более того, чтобы защитить себя от строк, мы добавляем предыдущее условие, как я упоминал ранее вот о чем я говорю
Я не понимаю, почему все используют map (lambda x: list (x), other) - разве это не эквивалентно map (list, other)? Встроенный список вызывается ...